

— 6 min de lectura
Escribimos esto para Google Cloud, pero realmente aplica para AWS también o Azure, ya que todos tienen servicios muy parecidos para lo que queremos hacer, pero vamos a centrarnos en Google Cloud que es lo que nosotros usamos a diario.

A poco que manejéis cierta infraestructura, tengáis desarrollos para multiples clientes con proyectos de prueba, máquinas de preproducción, despliegue con artefactos, etc, al final la factura de infraestructura va subiendo y puede llegar a ser un problema. En cualquier caso, aunque no sea un problema y podemos pagarlo, ¿por qué pagar de más? en algo que es sencillo controlar. Todo lo que vamos a mostrar aquí es automático y, una vez configurado, no hace falta darle apenas seguimiento (aunque también voy a enseñar cómo podemos tener claro si ha funcionado bien o no).
Almacenamiento en Google Cloud Storage
Tanto para desarrollo como para almacenar artefactos, ficheros de clientes, etc, es bastante probable que utilicemos algún servicio como Cloud Storage o Amazon S3.
Esto es muy común si vamos a tener más de una máquina sirviendo una aplicación, ya que no podemos tener determinados ficheros compartidos en local y habrá que tenerlos en un sistema distribuido de ficheros. Antes de llegar a Producción es muy probable que tengamos sistemas de pruebas, entornos de pre-producción, ficheros subidos para un despliegue, etc. Es en este caso en el que es bastante probable que, si no hacemos nada, estos ficheros acaben almacenándose eternamente (y paguemos por ello), sin que haga falta. Aunque el coste de S3 o de Cloud Storage es bajísimo, no cuesta nada configurar estas carpetas para que se borren al cabo de un tiempo. En ambos casos, tanto Amazon S3, como Cloud Storage, lo llaman lifecycle. Ahora explico como hacerlo para Google y podéis encontrar como hacerlo para Amazon S3 aquí.
Desde aquí pueden añadirse reglas nuevas y, en el caso de los ficheros que comentábamos, lo más sencillo es marcarlos para que se borren al cabo de un tiempo.

En este ejemplo hemos borrado los ficheros, a los 60 días, pero en algunos casos, como en logs o backups, quizá queramos cambiarles el sistema de almacenamiento a uno más económico pero al que no vayamos a acceder prácticamente nunca (esto es importante porque, en los almacenamientos más baratos, pagamos mucho más por el acceso a los datos que en el estándar, a cambio de que almacenar la información sea mucho más barato). Esto se ve mejor en las siguientes dos tablas:
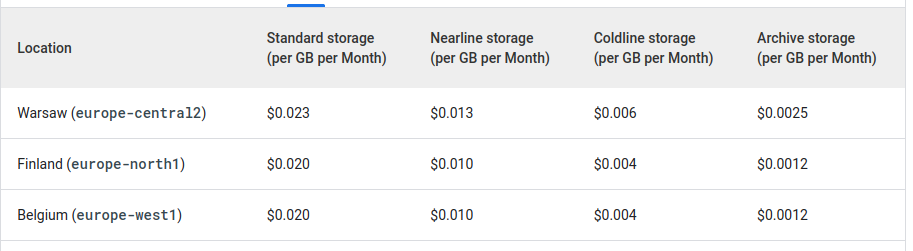
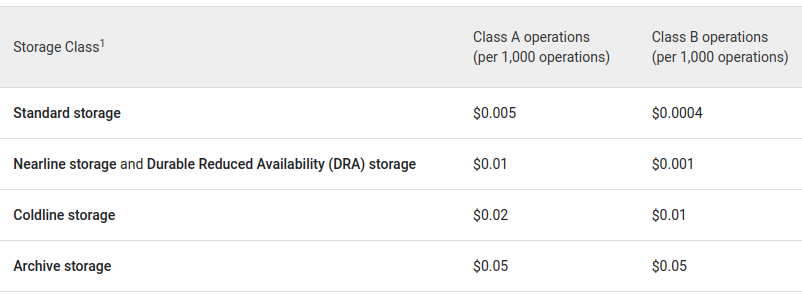
Como decía, es 10x más económico Archive que Standard, pero es también 10x más caro leer o escribir la información en el mismo, así que está pensado para cosas que vayan a quedarse mucho tiempo sin tocarse (de ahí el nombre). Por otro lado, también hay un compromiso de tiempo de almacenamiento, en el caso de Archive los datos tienen que estar por lo menos 365 días almacenados.
Hemos visto como crear las reglas desde consola, pero lo normal es que creemos los buckets por código o usando Terraform o algo similar. En estos casos, lo ideal es definir las reglas de Lifecycle directamente en la creación del bucket (o carpeta). Para ello, tenemos que crear un fichero con la configuración que queremos de reglas.
Un json sencillo para borrar objetos a los 60 días, sería:
{
"lifecycle": {
"rule": [
{
"action": {
"type": "Delete"
},
"condition": {
"age": 60
}
}
]
}
}y luego, creamos el bucket con el comando que usemos normalmente y lo actualizamos para añadirle el lifecycle:
gcloud storage buckets update gs://BUCKET_NAME --lifecycle-file=LIFECYCLE_CONFIG_FILEAhorro en máquinas de Compute Engine
Lo siguiente es cómo ahorrar en máquinas de Compute Engine o despliegues que hagamos para probar cosas con clientes, demostraciones, despliegues para desarrollos nuestros que estemos probando, etc. Para esto hay varias cosas, por un lado los descuentos por compromiso de uso y, por otro, la planificación de instancias o Instance Schedule.
El planificador de instancias nos permite apagar y encender instancias a determinadas horas, determinados días de la semana. Las instancias tienen que estar en la misma región que el planificador.
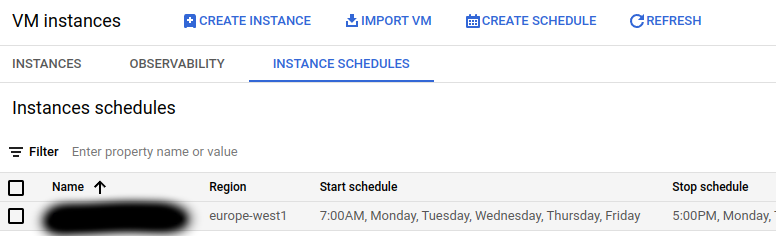
En el ejemplo anterior, encendemos las máquinas a las 7am y las apagamos a las 5pm, porque esto es una máquina que solo usaremos durante el trabajo y solo entre semana. En cualquier caso, obviamente, si alguien necesita usarla fuera de esas horas siempre puede encenderla manualmente.
El planificador puede conectarse a más de una instancia, siempre que, como ya decía, estén en la misma región.
Solo con la planifcación anterior, las máquinas estarían apagadas casi un 70% del tiempo, con el correspondiente ahorro. Google también nos cobrará por el espacio que ocupe el disco el tiempo que estén apagadas, pero salvo que sea un disco muy grande no debería ser mucho dinero.
Los descuentos se encuentran en la pestaña de Billing:
y nos permiten contratar compromisos de uso (por años) de máquinas a cambio de descuentos. Se puede usar el recomendador que tiene Google para ver las sugerencias de optimización que te dan. Si estás en medio de un cambio de infraestrucura en cualquier caso, es mejor esperar a haber terminado de cambiarlo todo y luego con algo de tiempo revisar esas recomendaciones y ver si tiene sentido contratar alguna.
AppEngine y CloudRun
Una alternativa para despliegues de pruebas o servicios de uso puntual es utilizar alguna infraestructura serverless con la idea de pagar solo por el tiempo que la estemos usando. De cara al ahorro, hay un par de cosas que hay que tener en cuenta si lo hacemos con esa idea en mente (estamos hablando siempre de infraestructura de prueba, servicios de uso puntual, etc, no producción).
Las arquitecturas serverless normalmente se definen con un escalado para permitir que aumenten o disminuyan en función del tráfico. En AppEngine por defecto el escalado es automático, y si vemos el ejemplo que ellos mismos ponen en su web:
<appengine-web-app xmlns="http://appengine.google.com/ns/1.0"></appengine-web-app>
<application></application>simple-app</application>
<module></module>default</module>
<version></version>uno</version>
<threadsafe></threadsafe>true</threadsafe>
<instance-class></instance-class>F2</instance-class>
<automatic-scaling></automatic-scaling>
<target-cpu-utilization></target-cpu-utilization>0.65</target-cpu-utilization>
<min-instances></min-instances>5</min-instances>
<max-instances></max-instances>100</max-instances>
<max-concurrent-requests></max-concurrent-requests>50</max-concurrent-requests>
</automatic-scaling>
</appengine-web-app>En este ejemplo tendríamos un mínimo de 5 instancias siempre en ejecución. Hay otro parámetro, aunque en este caso no lo ponen, que es min-idle-instances para determinar el mínimo de instancias listas pero no activas, por si hubiera un pico de tráfico mandar parte del mismo a esas instancias (e ir preparando otras entre medias). Para ahorrar dinero en despliegues como los que comentábamos, pruebas, etc, lo ideal es poner ambos parámetros a cero.
CloudRun es más sencillo porque por defecto no tendremos instancias paradas pendientes de recibir peticiones.
En ambos casos la primera petición es más lenta, claro, porque tendrá que levantar una instancia nueva, pero ahorramos que es de lo que se trata en este caso 😊.
Otro punto a tener en cuenta, en ambos casos, es el de las ejecuciones periódicas (tipo cron o similar), si estamos en un entorno de pruebas o desarrollando algo nuevo, tener en cuenta el configurar ejecuciones periódicas con mucha menor frecuencia que en Producción, porque si no estaremos pagando todo el rato por las instancias que se levanten para realizar esas ejecuciones.